
34: Instruction Set Architectures


After a quick few drinks at the bar in celebration of how far we’ve come, let’s get back to work. We are still nowhere near the modern computer.
This next article is about deciding what instructions to include in a processing unit in general, and not just the central processing unit. An Instruction Set Architecture (ISA) may sound scary, as would any phrase with the word “architecture” in it, but do not be alarmed just yet. Truly understanding the architectures of instruction sets is not trivial, but it usually is also not necessary, especially because the architectures, in part, have to do with how much physical space is available on a CPU/ASIC and what instructions are needed.
Simply put, an instruction specifies a circuit to be run, by some bit combination, for example, 92 (1011010). The circuit can be some operation such as a SHIFT, an ADD, a memory MOVE operation, or any other thing a processing unit can execute. Using a little math, we know that from 8 bit instructions, one can construct 2⁸=256 different numbers, meaning that a computer with 8-bit instructions can only contain up to 256 unique circuits that it can execute. The whole set of possible instructions one can execute, created via digital circuit design, is known as an instruction set architecture.
An 8-bit processor, as one might hear, however, does not mean that the ISA has opcodes (operation codes) of length 8. Instead, this number refers to the size of the registers within the CPU.
Given that the register with which we are working has a pre-specified number of bits that can fit into it, if you tried to run a (binary) program that includes instructions that include more bits than the register has space for, it would be impossible to execute on such a processor. An instruction that requires 16 bits to express the circuit needing running, clearly won’t be able to be executed on a register with only 8 bits.
Unfortunately, going the other way usually also doesn’t work. Suppose one had a 16-bit processor instead of an 8-bit one. One can fit 8-bit instructions into a 16-bit slot of SRAM, but the sets of opcodes do not necessarily build on each other, i.e., they can be completely different. 16-bit architectures are not necessarily only extensions of 8-bit ones (and usually aren’t) but have instructions that are equivalent to the 8-bit ISAs and require 16 bits to call, as they are numbered in different ways.
For example, a simple “ADD” operation might be denoted by the opcode 1100 0110 in the 8-bit ISA, but the same instruction might have the opcode 1001 0010 1010 0101 in the 16-bit ISA, which is unspecifiable in 8 bits. If tried to be executed*, the processor will execute the wrong instructions and won’t execute the intended program. This is one of the main reasons why old programs do not function on more modern computers.
One can still usually get the program running by using what’s known as an emulator or a virtual machine (these are software that simulates some given system). The lower bit number instruction might not exist on the high number bit processor, but if one has a 16-bit architecture and wants to run an 8-bit ISA, one can usually map the 8-bit ISA to instructions of the 16-bit ISA, and vice-versa. This way, whenever the emulator wants to execute an instruction, the instruction is “translated” to a 16-bit instruction before being executed.
Running an emulator is usually a tiresome activity, which is why most software, for this reason, has multiple versions of their software in different instruction set formats (16-bit, 32-bit, 64-bit, etc.) so that one can always download/install the software with the correct ISA for one’s computer.
So we can, in theory, run 8-bit programs on 16-bit processors if every instruction of the processor exists in some shape or form in the 16-bit ISA. We could, in theory, “translate” a 16-bit ISA program to an 8-bit processor if all instructions exist on that processor. This is usually not the case, hence why in principle, you cannot run a higher number ISA with a lower number ISA. Even with ISAs with the same length architecture, two programs with the same length opcode, written for different processors, also cannot run without an emulator.
This is, unfortunately, what happened in the early days of computers: many chip makers created their ISAs, which meant that often times “program portability” between computers using different processors was difficult to do and sometimes even impossible, as emulators hadn’t been written for every ISA to every other one.
For this reason, ISAs lie at the heart of computers and define what a computer is theoretically capable of doing. CPUs with fewer instructions have less flexibility, which is why computers have grown from having 8-bit processors to having 64 bits. Then again, with more instructions, you’d also have more wires, so you’d have to compress the wires more and more if you want them to take up the same amount of space. So Moore’s law/Dennard’s scaling made processors smaller, but at the same time, chip manufacturers included more and more instructions in them, and even combined several circuits one after another (sequentially).
In general, there are two ways in which computers with ISAs can be implemented and classified:
Reduced Instruction Set Computers (RISC): computers that only include instructions that perform a single action, e.g., add two numbers, shift bits by 1 to the left, etc.
Complex Instruction Set Computer (CISC): A computer that has instructions that can execute multiple insular instructions at the same time, e.g., add and store, shift three times then XOR, “save to disk”, etc.
Nevertheless, with just a few circuits, one can execute just as many operations as an ISA with many instructions. It’s just a question of how long it takes: multiplication after all, is just iterative addition, while shifting bits to the left is equivalent to shifting bits far enough to the right (if cyclical shifting is present). Having more instructions, therefore, does not necessarily mean more functionality, but it does suggest a higher performance by replacing multiple instructions in clock cycles with a single one in fewer cycles. This is what is meant by a CISC.
Still, it doesn’t mean that RISCs are inferior to CISCs. Some computer systems may only need basic instructions, such as adding and subtracting, rather than more complex instructions, such as encryption or even the translation mechanism of ISAs. With simpler circuits, the maximum time it takes for RISCs to execute an instruction is lower (shorter wires), which means that the clock speed can be increased, leading to higher performance. The chips are also smaller, which means we can include them in embedded systems, such as vaccines†.
Because of the enormous number of uses for computers, most commercial computers are CISC, and initially, many of them were built using custom processors. To avoid programs not working on different chips (one that may not be RISC, for example), Intel and AMD, the primary manufacturers of processors, came up with a grand solution: instead of creating new ISAs for every new processor, they kept all instructions from previous processors and added on more instructions, when needed. Such a technique allows for backward compatibility (and compatibility in general), meaning that programs requiring “older ISAs” can run on this new processor, making every program created on it runnable for every newer version. Whether or not a digital circuit has efficiently implemented a specific instruction takes second place to the software actually working.
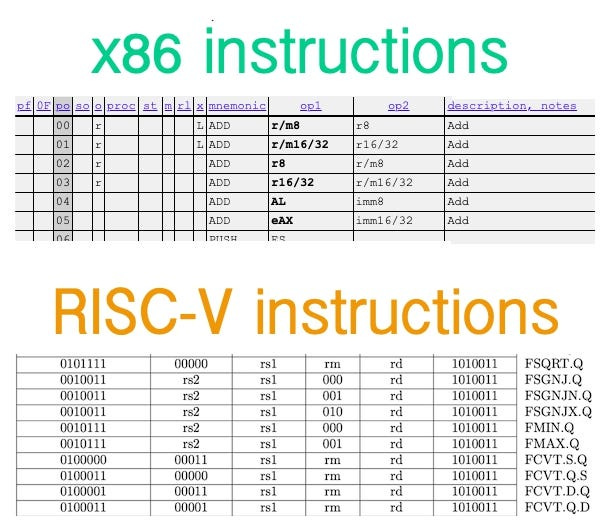
This process of extending instructions started in 1978. Since then, many more instructions have been added for newer processes, which is why x86 is so powerful. It includes all instructions ever created for Intel’s line of processors, and there are so many that a relatively large reference manual for instructions has been written to track them all.
In such an ISA manual, one will see above 1'000 operations. Because of the sheer immensity of possible binary operations and shift combinations from register to register, and and and, there is no point in memorizing these in detail. Unless you weirdly want to be the expert of experts in this thing or want to write a compiler.
In the manual, several ADD opcodes differ in what specific register the processor should save data (as multiple registers can hold data), with plenty of other painstaking information that the normal software developer does not need to worry about. Barely anyone does. People tend to use assembly code, a low-level programming language, to read opcodes and interpret binary files in general.
And this is exactly where we arrive at some ontological changes/abstraction. From here on out, when talking about software, the lines between two very general views of of computers, hardware, and software, begin to blur. Hardware always refers to the physical wires, printed circuit boards (PCB), number of bits in SRAM caches, etc., whereas software always refers to information/arrangement of instructions that SRAM and non-volatile memory hold. But an opcode is some software that represents an instruction, a hardware component, which means that when programming a high level languages, these opcodes are completely hidden from view, making the actual running of programs opaque, even to experienced engineers.
But let’s stay with hardware for now. Discussions of software is completely different, and will require some time.
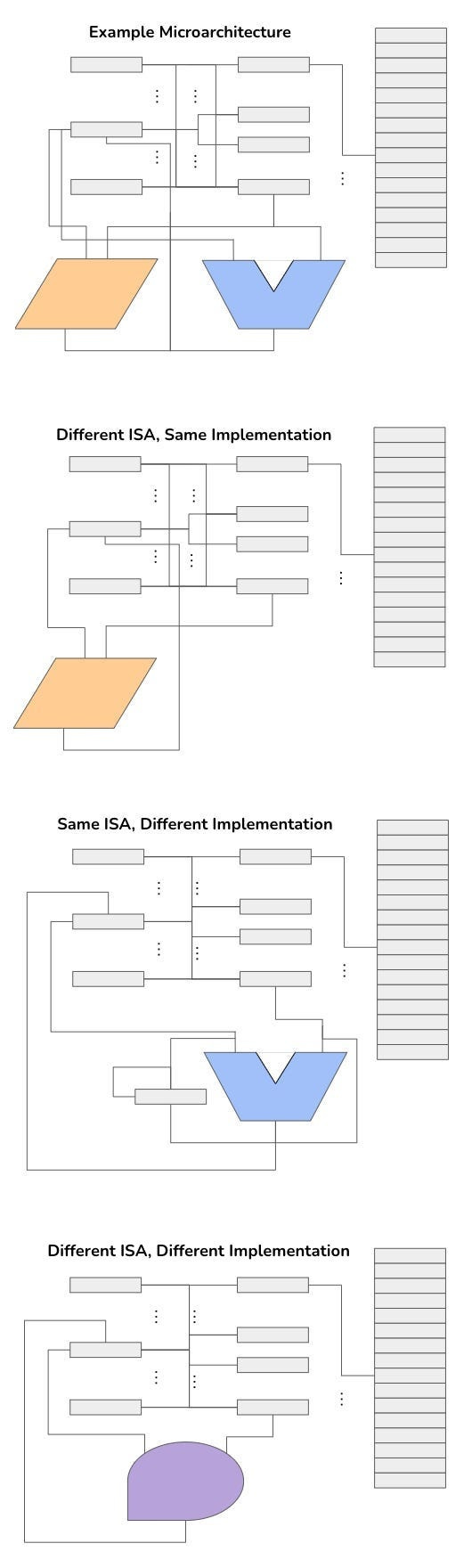
The key point of talking about software, is that while the software may be the same, the hardware implementation may be different, even with the same ISAs. A program written for a RISC can, in theory, be the same as one for a CISC, but be run on two different hardware chips, because the physical arrangement of wires and adders might differ. This arrangement of wires and circuits is known as a microarchitecture. Computer architecture refers to the “marriage” of the microarchitecture of a processor and its ISA.
Given how complex all of these concepts are, IT people generally prefer to avoid getting to know all of computer science and engineering. Knowing assembly code (or God forbid, the individual opcodes), in the modern world, will be seen as a worthless hassle. There are nonetheless plenty of worthy things to be learned by learning Assembly. Like with most learned things, the percentage of knowledge you need to get things done is very, very low (especially if you know a lot of things). The thing is, you don’t need to use assembly often. But when you need to use Assembly, you most definitely need it, with no other way around it, no alternative, no tricks up the sleeve to avoid it. Malware analysis, the act of figuring out how computer viruses for example, is only possible by reading the actual binary files, usually “translated” into Assembly.
While always presented as a single language though, is, in fact, a family of languages that differ depending on what ISA you are programming for. There there in fact, two main types of Assembly used for most computer architectures. But we are going to wait to look at Assembly for now, and stick to hardware.
Let us be satisfied that there is only 2 ISAs in widespread use for laptops and desktop computers: x86 (CISC) and ARM (Advanced RISC Machine). These allow us all to share software between one computer to another easily. Even so, software, it will turn out, can be more complicated than hardware as it incorporates anything and everything so far, and then much, much more.
Sure, easy-to-understand-and-execute programs can be written in programming courses online. You simply have no idea what’s really going on. At the same time, the act of learning and knowing what your computer is doing can send you down a road of darkness with no easy answers and few footholds to help. Rigorous groundwork that has been built for you over decades, even centuries, using methods that defy straightforward explanations.
You think computers are simple? Nope. All of this just keeps getting more complicated.
Stay tuned.
Footnotes
*On virtually any modern desktop, your computer will refuse to run the program is the ISAs do not agree. When trying to fill the remaining bits (such as simply including 0000 0000 at the beginning of the string), your computer would be executing random instructions, so that the load computer store cycle would not work. Because not all numbers specify instructions, one is bound to arrive very quickly at an instruction that is theoretically impossible to execute, and the processor throws an error at the deepest level of your computer. If not this, then you will likely break your computer by overwriting critical software.
†just kidding. This doesn’t happen.